Il existe une multitude de données circulant au sein des réseaux de télécommunications informatique.
La donnée est regroupée sous de nombreux formats.
Elles surviennent dans n’importe quel domaine (web service, fichiers Excel…).
Pour comprendre ces données, il faut les cataloguer, les documenter et les identifier.
Il faut aussi déterminer si elles sont importantes ou non.
Au sein de Data Inventory, les données à identifier proviennent de jeux de données appelé datasets.
Afin d’identifier les données et de corriger les erreurs,
on utilise le logiciel Data Inventory. Grâce à une analyse sémantique, il détecte les erreurs que peuvent avoir certaines données.
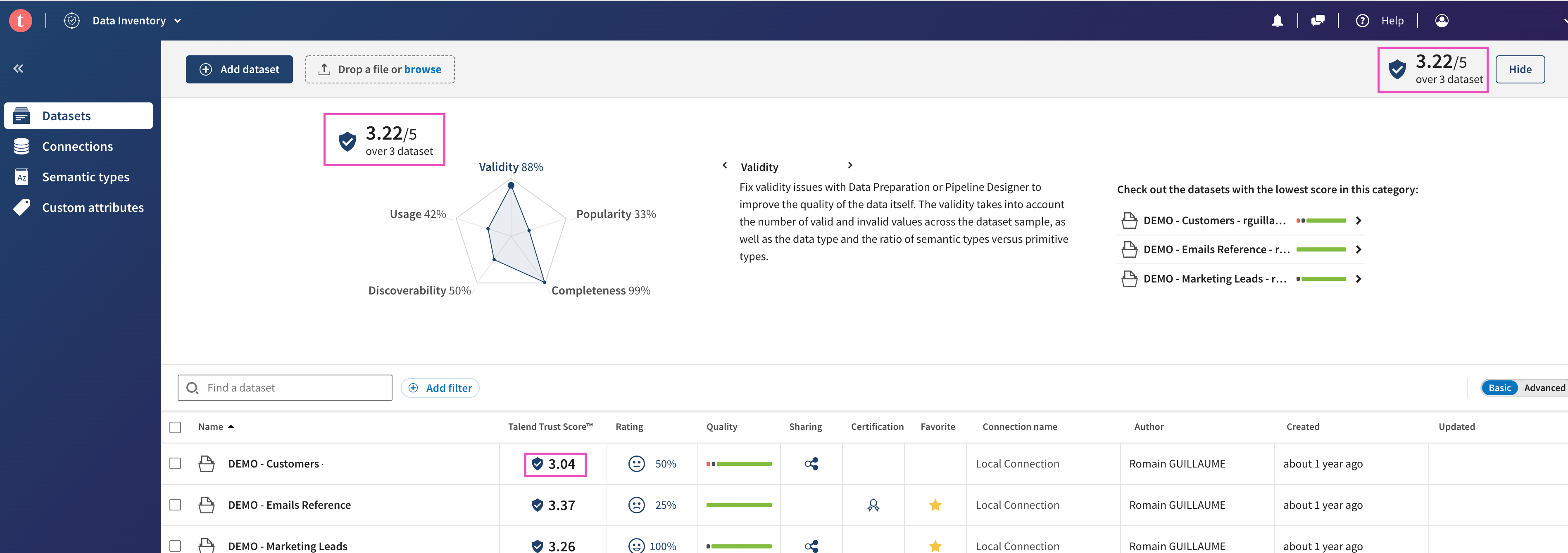
Chacun des datasets possèdent un indice de confiance appelé Trust Score.
Il se base sur 5 critères : Validity, Popularity, Completeness, Discoverability et Usage.
Ces datasets peuvent aussi être partagés par les utilisateurs.
Sur la vue d'un dataset, on peut observer ce niveau de confiance. Il est établi sur une échelle de 5 points.
Il renseigne donc sur la santé et l'intégrité des données concernant un dataset.
On retrouve aussi cet indice de confiance global sur un ensemble de datasets.
L'indice de confiance d'un dataset peut-être amélioré grâce à la documentation :
la personne qui traite les informations des données peut augmenter l’indice de qualité.
L'indice de confiance peut aussi être amélioré grâce à la correction des données avec les deux autres produits Data Prep et
Data Stewardship.

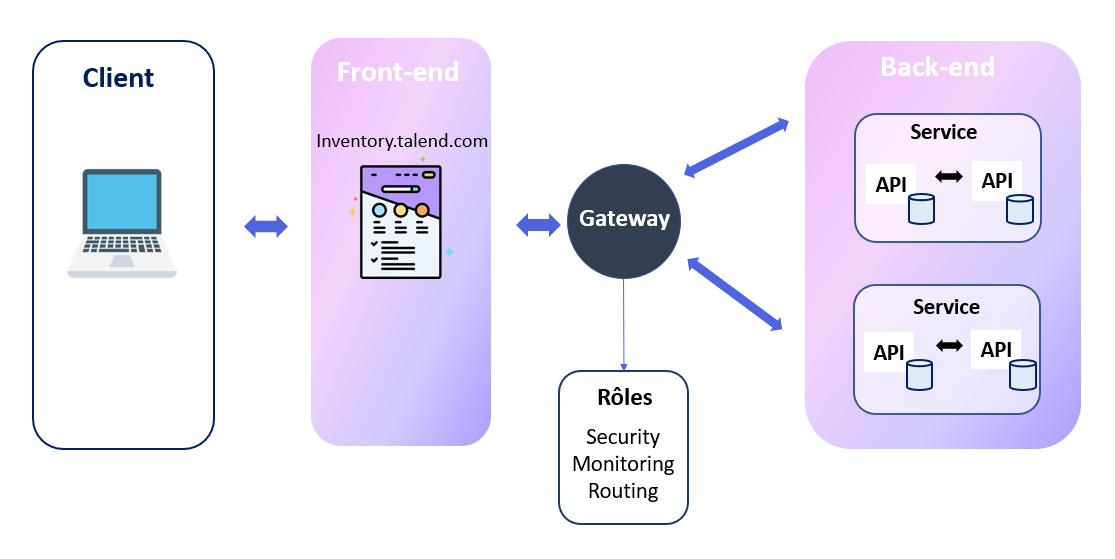
En fonction des actions de l’utilisateur sur Data Inventory, l’information passe d'abord par la Gateway qui
effectue divers contrôles avant de rediriger vers un service en particulier.
Chaque service va dépendre de plusieurs API avec leur propre base de données qui vont
communiquer entre elles. Ici, la passerelle est le premier niveau
de sécurité et effectue plusieurs contrôles comme indiqué sur le schéma.